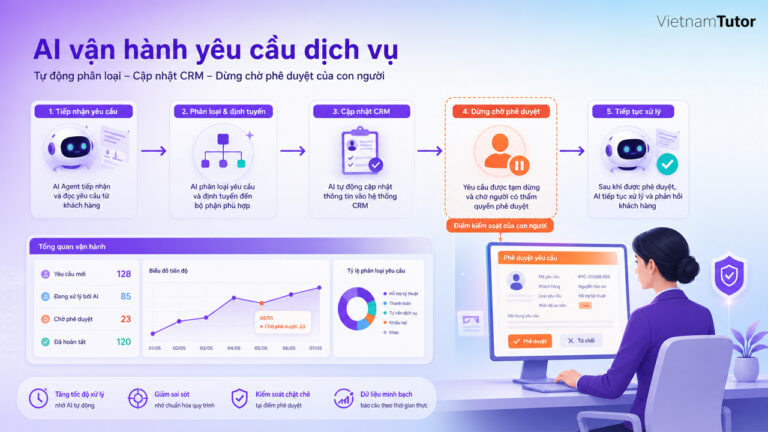
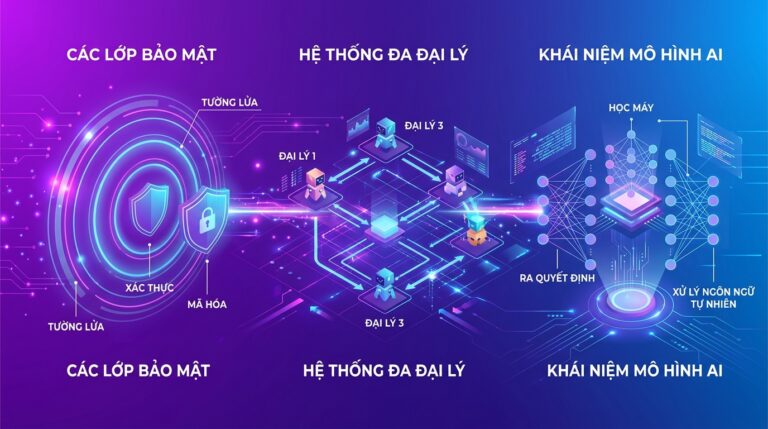
AI Agent của doanh nghiệp có lúc trả lời đúng giọng thương hiệu, nhưng hôm sau lại dùng policy cũ hoặc viện dẫn tài liệu không liên quan? Vấn đề thường không chỉ nằm ở prompt. Agent có thể đang nhận quá ít, quá nhiều hoặc sai loại ngữ cảnh cho công việc hiện tại.
Quản lý ngữ cảnh AI Agent là cách tổ chức và nạp đúng dữ liệu, quy tắc, công cụ và lịch sử cần thiết vào đúng thời điểm. Bài viết này giúp bạn xây cấu trúc năm lớp dễ vận hành cho SME, để output ổn định hơn mà không biến mỗi yêu cầu thành một prompt khổng lồ.

Tóm tắt nhanh
- Prompt là chỉ dẫn; context là tập dữ liệu, quy tắc, công cụ và lịch sử agent được phép dùng.
- Nên chia context thành năm lớp: core, knowledge, task, tools và memory.
- Không nạp toàn bộ tài liệu cho mọi yêu cầu; chỉ inject phần liên quan theo nhiệm vụ.
- Nội dung tĩnh nên đặt trước nội dung biến đổi để tận dụng prompt caching tốt hơn.
- Mỗi nguồn context cần owner, ngày cập nhật, quyền truy cập và cách đánh giá chất lượng.
Quản lý ngữ cảnh AI Agent là gì?
Quản lý ngữ cảnh AI Agent là quá trình chọn, tổ chức, cập nhật và cấp quyền cho thông tin agent dùng khi xử lý một nhiệm vụ. Context tốt giúp agent biết đâu là policy bắt buộc, đâu là tài liệu tham khảo và đâu là dữ liệu chỉ dùng cho một case cụ thể.
- Context
- Toàn bộ thông tin agent nhận được ngoài yêu cầu tức thời: chỉ dẫn nền, tài liệu, dữ liệu nghiệp vụ, lịch sử cần thiết, tool description và quyền hành động.
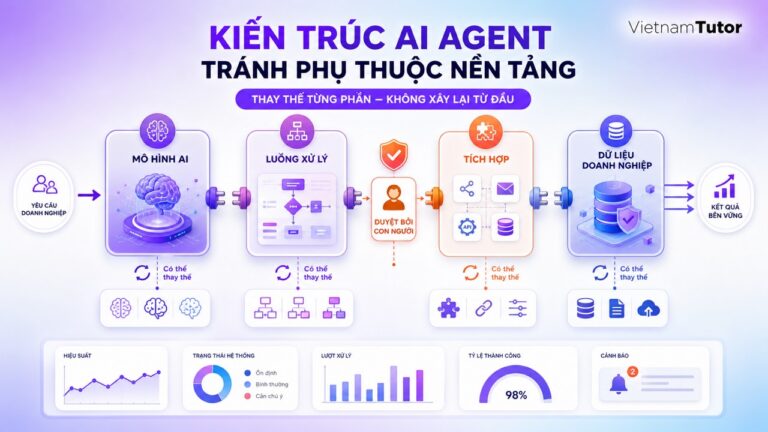
MindStudio đề xuất cấu trúc folder cho agentic context management gồm core, knowledge, tasks, tools và memory, kết hợp conditional injection để chỉ nạp phần cần thiết. [1] Cách tiếp cận này phù hợp với SME vì đội vận hành có thể nhìn thấy nguồn tri thức thay vì để mọi thứ nằm lẫn trong một prompt dài.
Nếu bạn mới tìm hiểu AI Agent, bài AI agents tự động hóa doanh nghiệp giúp phân biệt agent với automation theo rule. Điểm quan trọng là agent càng có nhiều quyền và nhiều nguồn dữ liệu, quản lý context càng cần rõ.
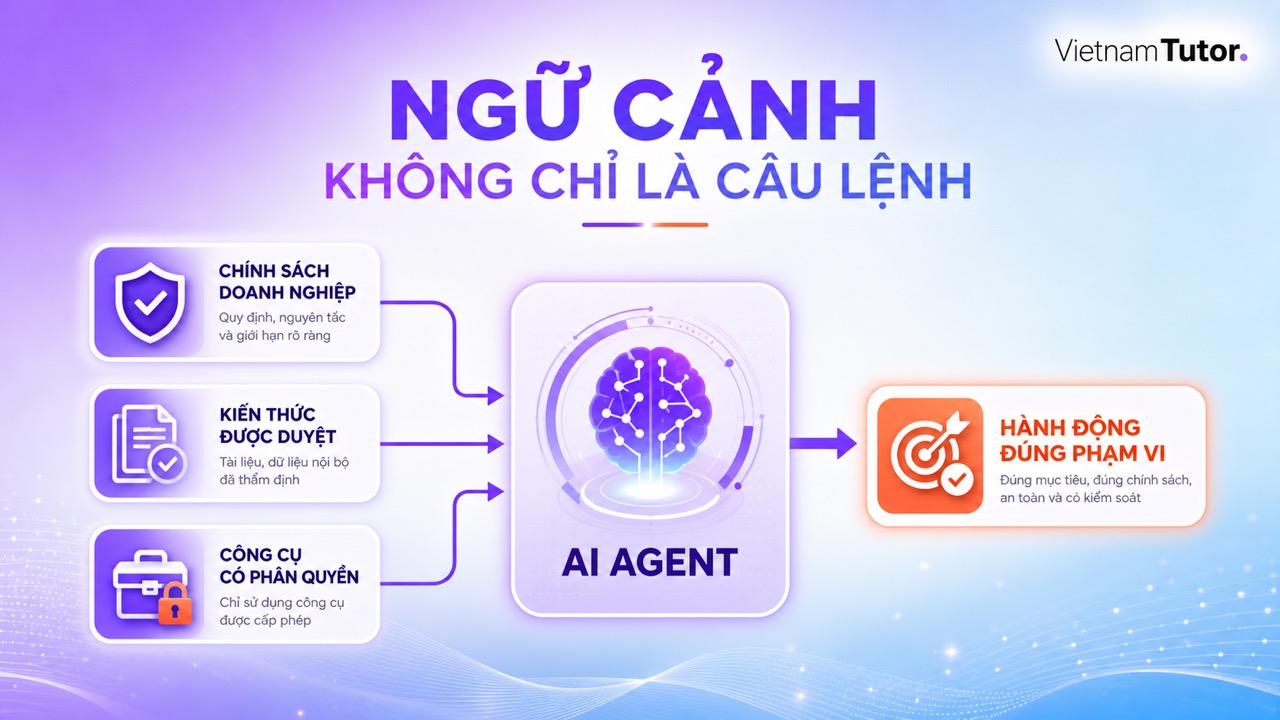
Năm lớp context doanh nghiệp cần tổ chức
Hãy chia context thành năm lớp: core, knowledge, task, tools và memory. Mỗi lớp có vòng đời và quyền truy cập khác nhau, vì vậy tách lớp giúp đội ngũ cập nhật đúng chỗ và giảm rủi ro dùng nhầm dữ liệu.
| Lớp | Nội dung | Ví dụ cho doanh nghiệp |
|---|---|---|
| Core | Vai trò, nguyên tắc, điều cấm, giọng thương hiệu | Không cam kết giảm giá nếu chưa có phê duyệt. |
| Knowledge | Tài liệu đã duyệt, FAQ, chính sách, hướng dẫn | Gói dịch vụ, phạm vi bảo hành, quy trình hỗ trợ. |
| Task | Dữ liệu của yêu cầu hiện tại | Nội dung form, loại khách hàng, trạng thái ticket. |
| Tools | Công cụ được phép gọi và schema đầu vào | Tra CRM, tạo bản nháp email, đọc trạng thái đơn hàng. |
| Memory | Lịch sử cần thiết và dữ liệu được phép lưu | Sở thích kênh liên hệ, lần hỗ trợ gần nhất. |
Không phải agent nào cũng cần đủ năm lớp. Agent tổng hợp báo cáo tuần có thể cần knowledge, task và tool đọc dữ liệu, nhưng không cần memory dài hạn về từng khách hàng. Ngược lại, agent hỗ trợ chăm sóc khách hàng cần biết lịch sử gần nhất nhưng vẫn phải giới hạn dữ liệu nhạy cảm.
Mình khuyên bạn tạo owner cho từng folder hoặc collection: ai được cập nhật, ai duyệt, ngày rà soát tiếp theo và agent nào được truy cập. Đây là việc nhỏ nhưng giảm tình trạng “không ai biết agent đang đọc phiên bản nào”.
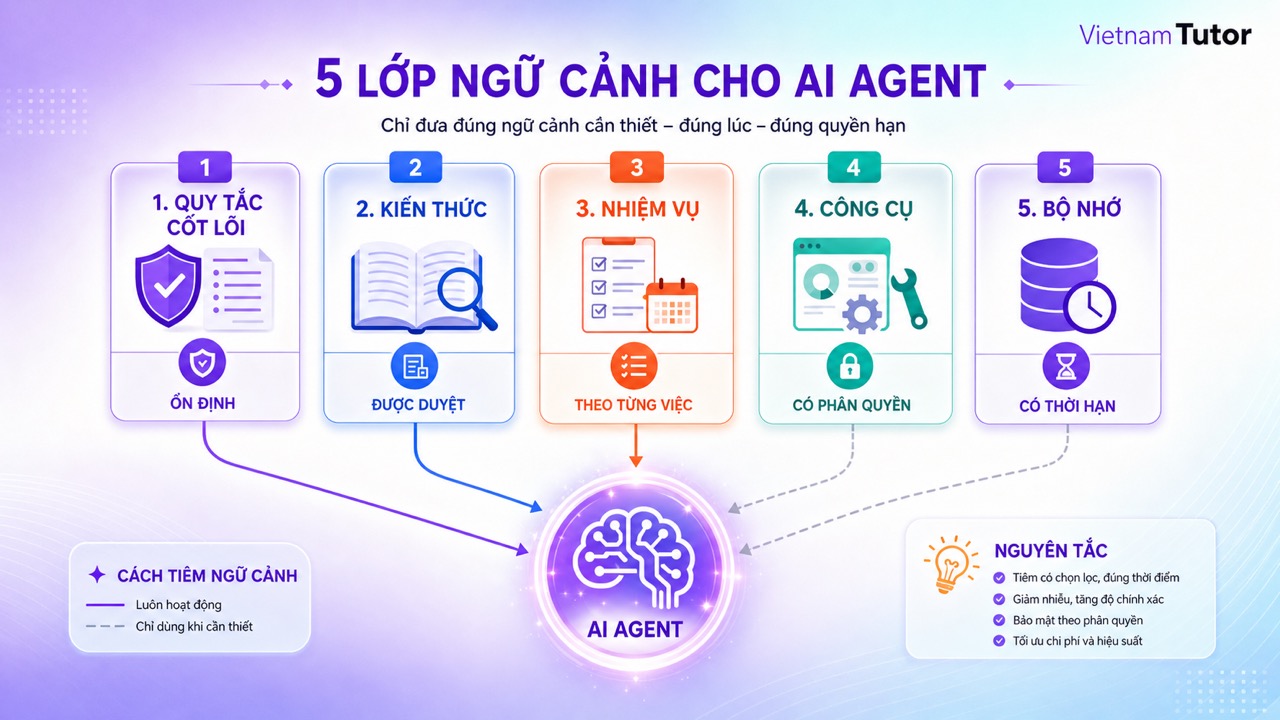
Vì sao không nên nạp toàn bộ dữ liệu cho AI Agent?
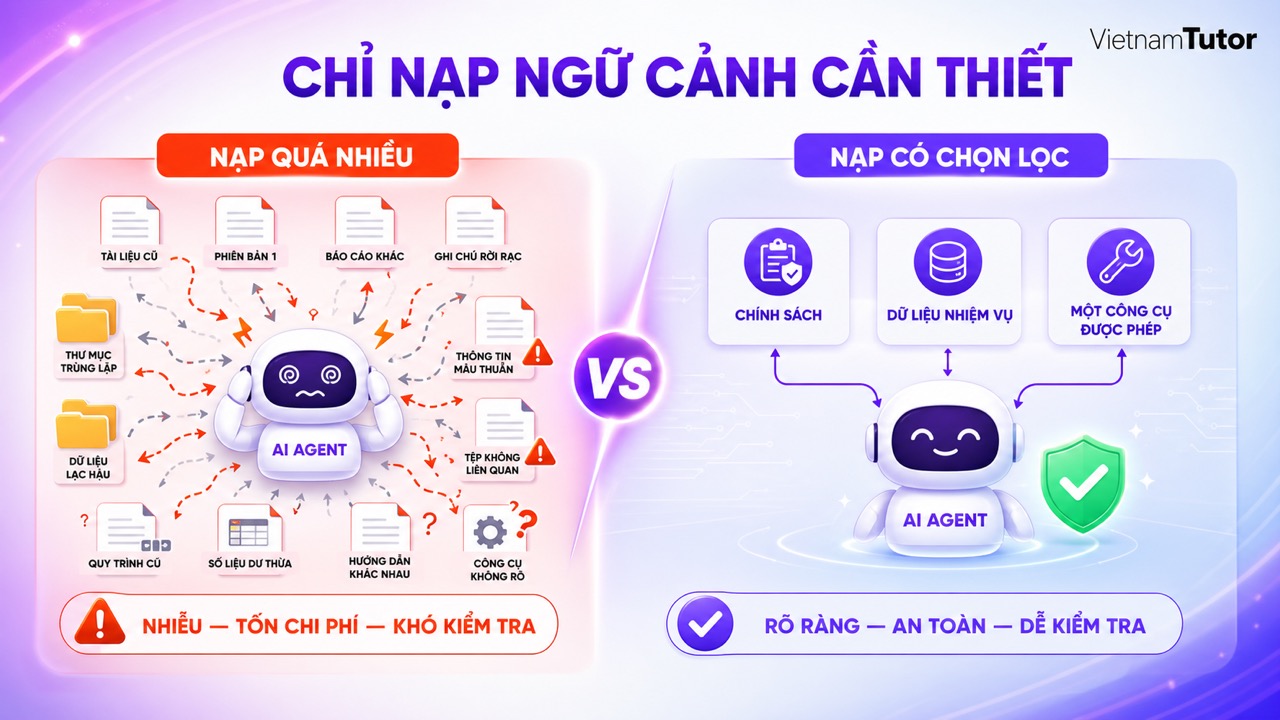
Nạp quá nhiều context có thể làm tăng chi phí, tăng độ trễ và khiến thông tin quan trọng bị chìm trong dữ liệu không liên quan. Agent cần đúng context, không cần mọi context.
OpenAI lưu ý retrieval có thể đưa vào context thông tin sai hoặc quá nhiều thông tin, làm chìm chi tiết quan trọng và có thể dẫn đến hallucination. [4] Đây là lý do knowledge base lớn chưa chắc tạo ra câu trả lời tốt hơn nếu không có bước lọc theo nhiệm vụ.
Ví dụ, agent trả lời câu hỏi về thời gian bảo hành website chỉ cần policy bảo hành hiện hành và dữ liệu hợp đồng liên quan. Nó không cần toàn bộ tài liệu marketing, lịch sử nội bộ hoặc file báo giá cũ. Nếu nạp tất cả, một đoạn lỗi thời có thể được ưu tiên nhầm.
OpenAI cũng khuyên đặt nội dung tĩnh ở đầu prompt và nội dung biến đổi ở cuối để tăng khả năng prompt cache hit. [2] Về mặt vận hành, bạn có thể giữ core rules ổn định, sau đó thêm context theo task ở cuối. Cách tổ chức này vừa dễ kiểm tra vừa tiết kiệm hơn.
Làm sao giữ đúng policy và giọng thương hiệu?
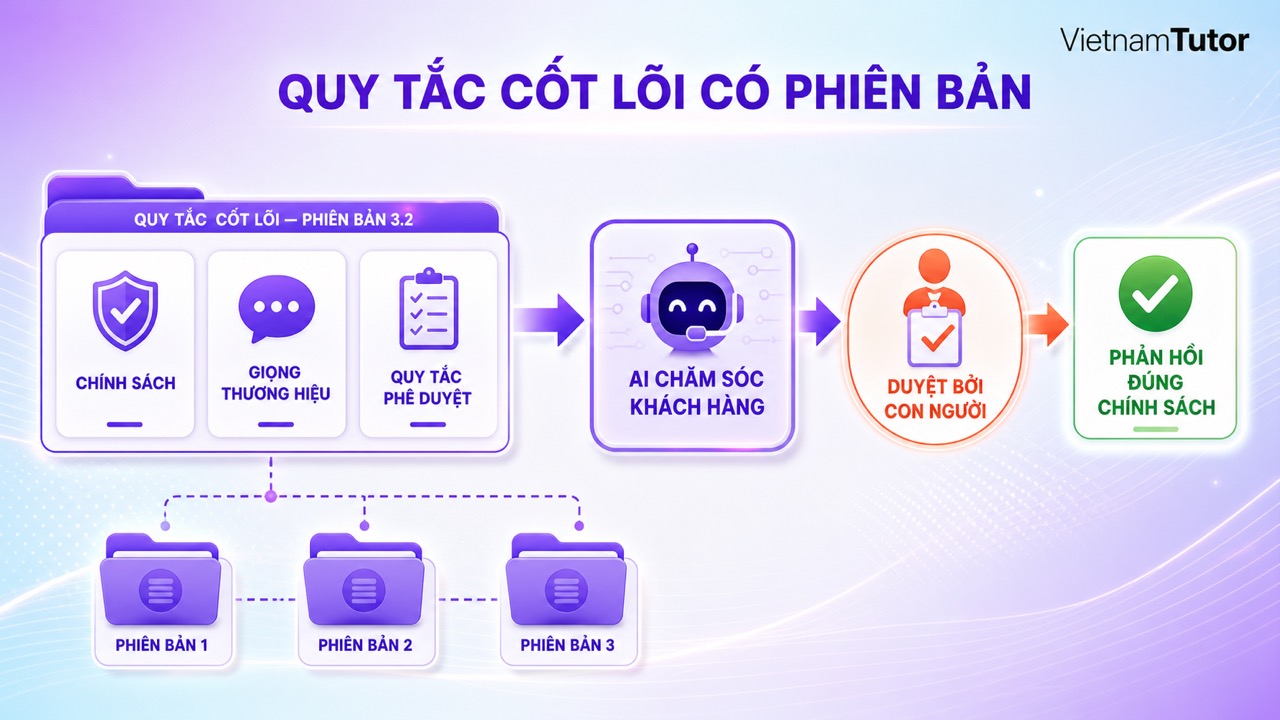
Giọng thương hiệu và policy cần nằm trong lớp core có version rõ, không sao chép rải rác trong từng prompt. Task prompt chỉ nên mô tả việc cần làm và dữ liệu của case hiện tại.
Hãy tách ba loại chỉ dẫn thường bị trộn lẫn: nguyên tắc bắt buộc, phong cách diễn đạt và dữ liệu nghiệp vụ. Ví dụ, “không tự gửi báo giá” là policy; “viết ngắn, rõ, chuyên nghiệp” là brand voice; “khách hàng đang quan tâm gói bảo trì” là task context.
Khi ba loại này được tách lớp, đội marketing có thể cập nhật tone mà không sửa logic workflow. Đội vận hành có thể đổi policy duyệt báo giá mà không phải lục lại hàng chục prompt. Nếu doanh nghiệp đang chọn quy trình đầu tiên, bài ma trận chọn pilot tự động hóa giúp giữ phạm vi nhỏ và dễ đo.
Đừng quên version và ngày hiệu lực. Một policy mới cần thay bản cũ, nhưng log vẫn nên ghi agent đã dùng version nào cho từng case. Khi có phản hồi từ khách hàng, bạn mới truy được nguyên nhân thay vì đoán.
Context cần phân quyền và QA thế nào?
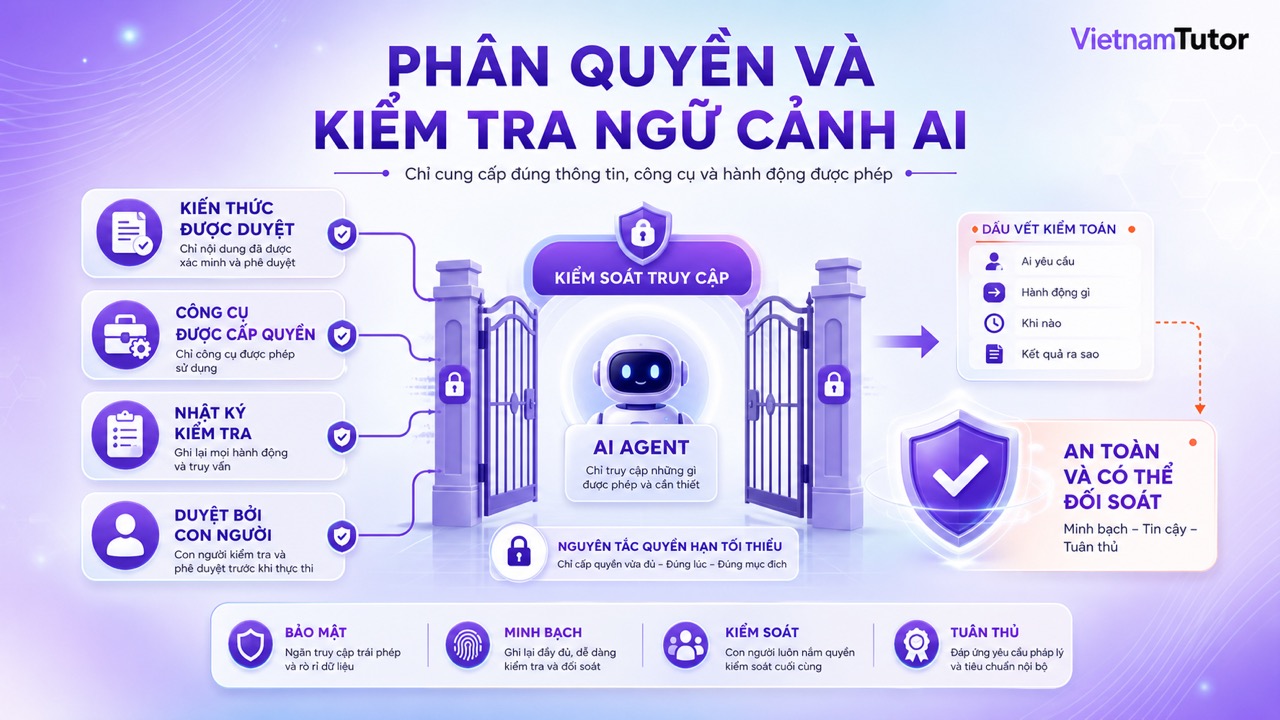
Mỗi nguồn context cần owner, quyền đọc, quyền cập nhật, ngày rà soát và bộ test đầu ra. Quản lý context không chỉ là tổ chức folder; nó còn là governance cho dữ liệu agent được phép dùng.
OpenAI node reference tách file search, MCP và guardrails thành các node khác nhau trong workflow. [5] Điều này phản ánh một nguyên tắc hữu ích: tài liệu, kết nối tool và kiểm soát an toàn là ba lớp riêng. Đừng xem một prompt dài là giải pháp thay thế cho phân quyền hoặc guardrail.
OpenAI RBAC docs mô tả quyền theo organization và project. [6] Với hệ thống của bạn, hãy áp dụng nguyên tắc least privilege: agent chỉ đọc collection cần thiết, chỉ gọi tool cần thiết và chỉ tạo hành động nháp ở giai đoạn đầu.
Nếu workflow gọi nhiều hệ thống, bài MCP là gì? giúp đội kỹ thuật hiểu lớp kết nối tool. Nếu bạn đang cân nhắc chi phí triển khai, đọc thêm bài ROI tự động hóa doanh nghiệp để đặt baseline trước khi mở rộng.
Bạn đang đọc bài thuộc chuyên mục Công nghệ của VietnamTutor, nơi mình chia sẻ cách ứng dụng AI có kiểm soát trong hoạt động doanh nghiệp.
| Kiểm tra | Câu hỏi | Hành động |
|---|---|---|
| Freshness | Policy còn hiệu lực không? | Gắn owner và ngày review. |
| Permission | Agent có đọc quá nhiều dữ liệu không? | Tách collection và giới hạn quyền. |
| Quality | Agent có trích đúng tài liệu không? | Chạy bộ test case đại diện. |
| Audit | Có truy được version context đã dùng không? | Lưu version ID trong log. |
Lộ trình 14 ngày triển khai context cho AI Agent
Trong 14 ngày, hãy chuẩn hóa một agent và một workflow trước khi mở rộng. Mục tiêu là tạo cấu trúc context có owner, quyền truy cập và bộ test đủ nhỏ để duy trì lâu dài.
- Ngày 1-2: chọn một workflow, liệt kê input, output, tool và hành động cần duyệt.
- Ngày 3-5: tách core, knowledge, task, tools và memory; xóa tài liệu trùng hoặc hết hiệu lực.
- Ngày 6-7: gắn owner, ngày review, quyền đọc và quyền cập nhật cho từng nguồn.
- Ngày 8-10: thiết kế selective injection theo loại task; đặt nội dung tĩnh trước dữ liệu biến đổi.
- Ngày 11-12: chạy 20-50 case đại diện, ghi lỗi trích dẫn, lỗi policy và lỗi giọng thương hiệu.
- Ngày 13-14: sửa context, chốt version đầu tiên và lập lịch review định kỳ.
Đừng cố xây knowledge base khổng lồ ngay từ đầu. Một agent dùng đúng 20 tài liệu đã duyệt thường có giá trị hơn agent đọc 2.000 file lẫn lộn. Đây là điều bạn nên biết: context tốt là context có chủ đích, không phải context nhiều nhất.
Nguồn tham khảo
- MindStudio: How to Use AI for Agentic Context Management
- OpenAI API Docs: Prompt caching
- OpenAI API Docs: Agents
- OpenAI API Docs: Optimizing LLM Accuracy
- OpenAI API Docs: Node reference
- OpenAI API Docs: Manage permissions
Các câu hỏi thường gặp
Quản lý ngữ cảnh AI Agent khác viết prompt thế nào?
Prompt là một phần của context. Quản lý context còn bao gồm tài liệu, dữ liệu task, memory, tool description, quyền truy cập, version và cách chọn nội dung theo từng yêu cầu.
Có nên cho AI Agent đọc toàn bộ drive nội bộ không?
Không nên. Hãy tách collection đã duyệt theo nhiệm vụ và chỉ cấp quyền tối thiểu cần thiết. Dữ liệu thừa có thể gây nhiễu và tăng rủi ro truy cập sai.
Memory của AI Agent nên lưu bao lâu?
Thời gian lưu tùy workflow và loại dữ liệu. Chỉ lưu phần cần thiết cho trải nghiệm hoặc vận hành, có policy xóa và tránh lưu dữ liệu nhạy cảm không cần thiết.
Bao lâu nên review context một lần?
Policy quan trọng nên review khi có thay đổi và theo lịch định kỳ. Với workflow vận hành thường xuyên, có thể bắt đầu bằng lịch review hàng tháng.
SME cần bắt đầu quản lý context từ đâu?
Hãy chọn một agent, tách năm lớp context, gắn owner và chạy 20-50 case đại diện. Đừng bắt đầu bằng việc gom toàn bộ tài liệu doanh nghiệp vào một nơi.
Agent của bạn đang sai ở policy, dữ liệu hay giọng thương hiệu? Hãy bắt đầu bằng cách tách năm lớp context và kiểm tra một workflow nhỏ. Nếu cần trao đổi thêm, để lại bình luận nhé; mình sẽ cùng bạn xác định lớp nên sửa trước.