Bạn có đang cho AI Agent đọc database thật, rồi bắt đầu lo khi nó cần sửa dữ liệu, chạy migration hoặc thử cleanup không? Với agent chỉ đọc, rủi ro còn kiểm soát được. Nhưng khi agent có quyền ghi, một câu lệnh sai có thể làm lệch dữ liệu dùng chung hoặc tạo lỗi khó truy vết.
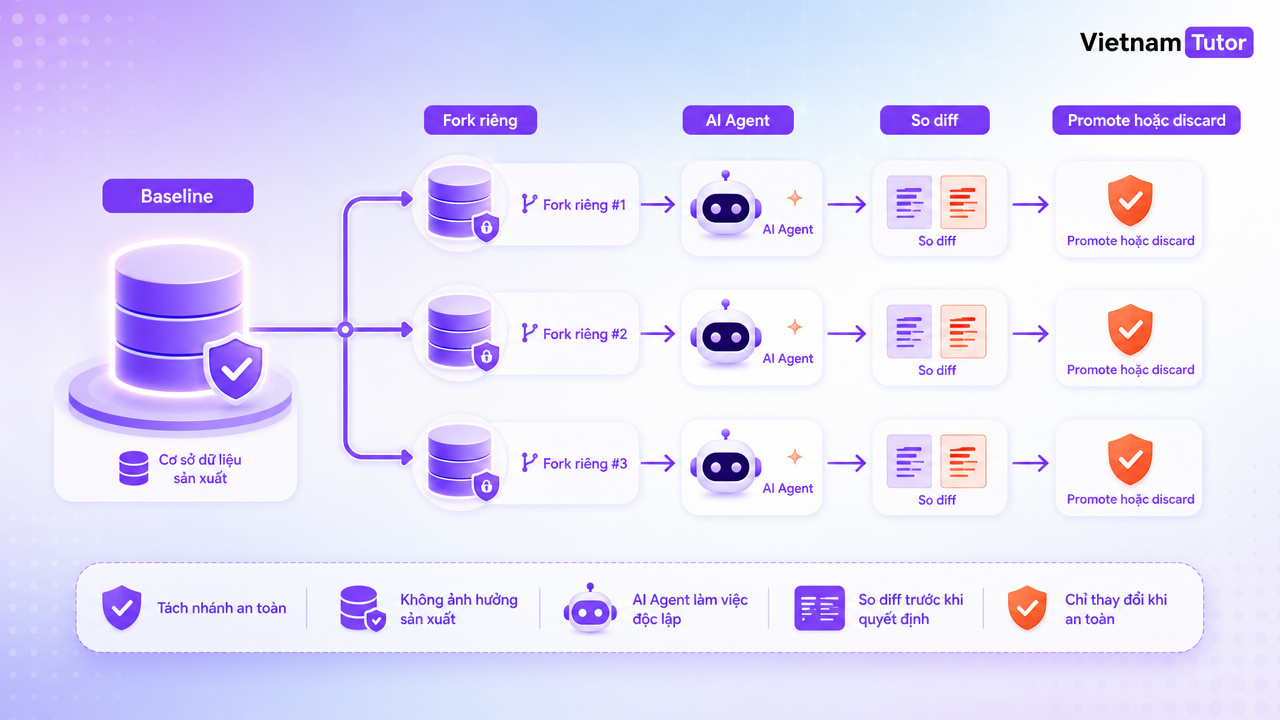
Cách tiếp cận tôi khuyên dùng là tạo môi trường database cô lập cho AI Agent: mỗi lần chạy có một nhánh database riêng, bắt đầu từ cùng baseline, làm việc trong vùng riêng, rồi cuối cùng so diff để quyết định discard hoặc promote.
Tóm tắt nhanh
- Môi trường database cô lập cho AI Agent là bản fork hoặc branch riêng để agent đọc và ghi dữ liệu mà không chạm trực tiếp vào database dùng chung.
- Pattern thực tế là baseline, fork, run, diff, rồi discard hoặc promote sau quality gate.
- Database branching khác transaction vì agent run có thể kéo dài, có nhiều bước và cần so sánh kết quả sau khi chạy.
- Neon, Xata, Supabase và một số nền tảng Postgres hiện đã hỗ trợ branching hoặc preview branch ở nhiều mức khác nhau.
- Database isolation chưa đủ; bạn vẫn phải cô lập cache, queue, search index, file storage và API có side effect.
Môi trường database cô lập cho AI Agent là gì?
Môi trường database cô lập cho AI Agent là một bản database riêng cho từng lần chạy agent, thường được tạo bằng database branching, snapshot restore hoặc schema/container riêng. Agent có thể đọc, ghi, thử migration và tạo dữ liệu tạm trong môi trường đó mà không làm thay đổi database nguồn.
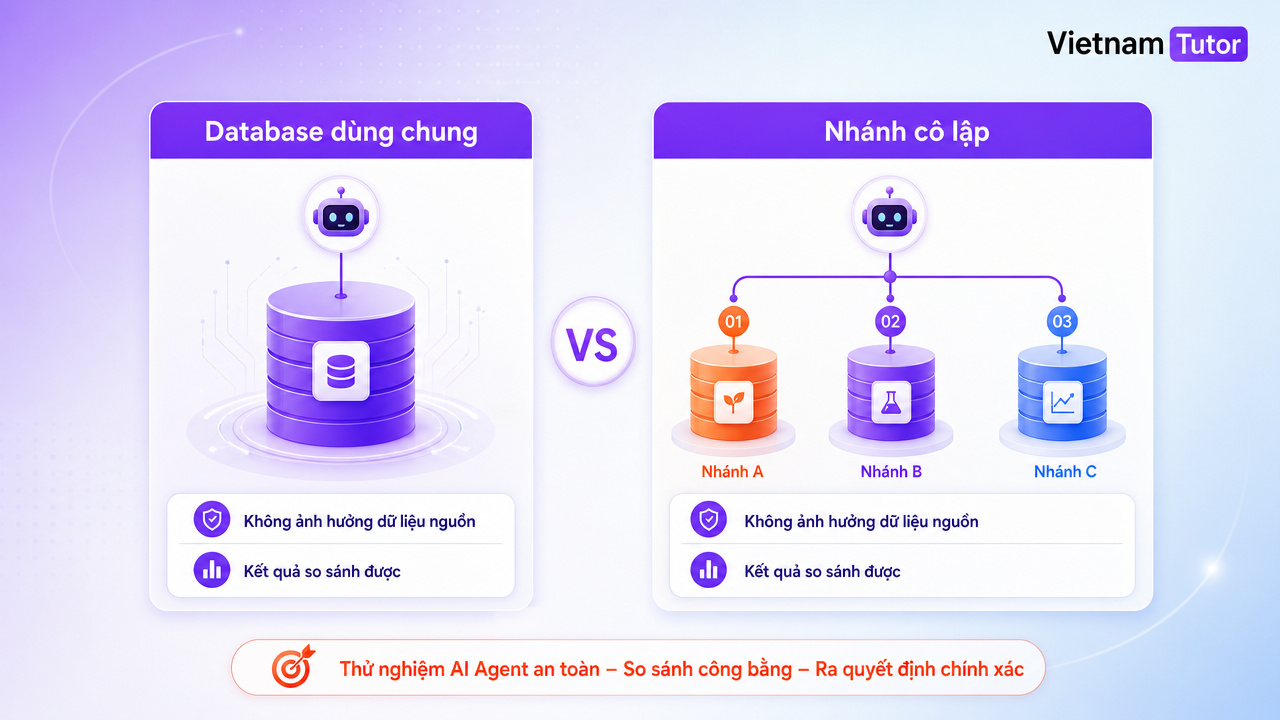
Hãy tưởng tượng bạn đang thử ba cấu hình agent để dọn dữ liệu khách hàng trùng lặp. Nếu cả ba cùng ghi vào một database staging, kết quả không còn công bằng: agent chạy trước đã làm thay đổi dữ liệu đầu vào của agent chạy sau. Nếu cả ba bắt đầu từ một baseline rồi chạy trên ba fork riêng, bạn so sánh được cấu hình nào sửa ít bản ghi sai hơn, chạy nhanh hơn và tạo ít exception hơn.
- Database branching
- Cách tạo một nhánh database độc lập từ database nguồn để thử thay đổi schema hoặc data, tương tự ý tưởng branch trong Git nhưng không nên hiểu là luôn merge tự động như Git.
- Baseline
- Trạng thái dữ liệu chuẩn, đã khóa hoặc version hóa, dùng làm điểm xuất phát chung cho nhiều lần chạy agent.
- Discard/promote
- Discard là xóa fork sau khi lấy kết quả. Promote là đưa thay đổi đã qua kiểm tra vào staging hoặc production theo quy trình kiểm soát.
Bạn đang đọc bài viết thuộc chuyên mục Công nghệ của VietnamTutor — nơi tôi phân tích cách dùng AI Agent, workflow tự động và hạ tầng dữ liệu theo hướng thực chiến cho doanh nghiệp.
Vì sao AI Agent dùng chung database dễ gây lỗi?
AI Agent dùng chung database dễ gây lỗi vì nhiều agent có thể ghi chồng dữ liệu, tạo trạng thái không xác định và làm kết quả thử nghiệm không còn tái lập được. Vấn đề không chỉ nằm ở prompt hay model; nó nằm ở kiến trúc state dùng chung.
MindStudio mô tả một lỗi rất quen thuộc trong multi-agent system: hai agent chạm cùng một record, một agent ghi đè kết quả của agent khác, rồi đội kỹ thuật mất nhiều thời gian debug hơn cả thời gian agent tiết kiệm được [1]. Trong hệ thống truyền thống, bạn có thể dựa vào transaction cho một thao tác ngắn. Nhưng agent workflow thường là chuỗi nhiều bước: đọc schema, chạy query, gọi tool, sửa dữ liệu, kiểm tra kết quả, thử lại. Chuỗi này có thể kéo dài vài phút hoặc lâu hơn.
Rủi ro lớn nhất là trạng thái trung gian. Agent A đang thử sửa bảng đơn hàng; agent B lại đọc chính dữ liệu đó để tạo báo cáo. Kết quả là bạn không biết lỗi nằm ở agent, dữ liệu đầu vào, prompt hay thứ tự ghi.
Vì vậy, với mọi agent có quyền ghi, tôi thường tách ba lớp quyền:
- Read-only production: chỉ đọc, không ghi, phù hợp cho hỏi đáp, phân tích và báo cáo.
- Writable fork: được ghi dữ liệu trong môi trường cô lập, phù hợp cho thử migration, cleanup, data repair hoặc benchmark.
- Controlled promotion: chỉ pipeline hoặc người duyệt mới có quyền đưa thay đổi qua staging/production.
Database branching khác transaction, backup và staging thế nào?
Database branching không thay thế transaction, backup hay staging; nó bổ sung một lớp môi trường ngắn hạn để agent thử thay đổi có side effect.
| Cơ chế | Dùng tốt cho | Điểm yếu khi dùng với AI Agent |
|---|---|---|
| Transaction | Đảm bảo một nhóm query ngắn thành công hoặc rollback cùng nhau | Không phù hợp cho workflow agent dài, nhiều tool call và cần so kết quả sau chạy |
| Backup | Khôi phục sau sự cố lớn | Thường nặng, không sinh ra để tạo môi trường thử nghiệm ngắn hạn cho từng run |
| Staging database | Kiểm thử tích hợp trước production | Nếu nhiều agent cùng ghi, staging vẫn bị nhiễu state như database dùng chung |
| Database branch/fork | Tạo môi trường riêng, so diff, discard hoặc promote | Cần tooling, cleanup, cost control và guardrail dữ liệu nhạy cảm |
Neon gọi branch là môi trường có data và schema riêng để bạn kết nối và sửa đổi [2]. Supabase branching phục vụ preview branch trong deployment workflow [4]. Xata cũng xem branch như môi trường để phát triển và thử thay đổi trước khi merge [3]. Điểm chung: bạn tách được vùng thử nghiệm khỏi nguồn chính, nhưng promote/merge, giới hạn và chi phí phụ thuộc từng provider.

Mô hình baseline, fork, run, diff, discard/promote hoạt động ra sao?
Pattern an toàn nhất là khóa baseline, tạo fork cho từng agent run, chạy agent trên fork, ghi lại diff và metric, rồi discard hoặc promote qua quality gate. Đừng để agent tự chọn database hoặc tự promote kết quả.
Luồng tối thiểu nên như sau:
- Baseline: chọn một trạng thái dữ liệu chuẩn. Với dữ liệu production, nên dùng dữ liệu đã mask hoặc anonymized thay vì clone nguyên thông tin nhạy cảm.
- Fork: tạo branch, schema hoặc container riêng cho từng run. Tên nên chứa run ID, agent ID và thời gian tạo.
- Run: truyền connection string của fork vào agent qua orchestrator. Không để agent đọc biến môi trường global trỏ về production.
- Diff: so thay đổi giữa fork và baseline: bảng nào đổi, bao nhiêu record bị sửa, constraint nào fail, migration có rollback được không.
- Gate: kiểm tra metric, test, audit log, dữ liệu nhạy cảm và output nghiệp vụ.
- Discard/promote: đa số run nên discard sau khi đã trích kết quả. Chỉ promote khi thay đổi qua được gate rõ ràng.
- Cleanup: xóa branch, snapshot, schema hoặc container tạm để tránh rò rỉ dữ liệu và phát sinh chi phí.
Neon docs nhấn mạnh việc poll operation đến trạng thái hoàn tất trước khi kết nối vào database đã restore, vì kết nối quá sớm có thể trỏ về trạng thái cũ [2]. Với agent workflow, chi tiết này rất dễ gây debug nhầm.
def run_agent_experiment(run_id, baseline_branch_id):
# 1. Tạo môi trường database cô lập cho lần chạy này
branch = create_database_branch(
parent_id=baseline_branch_id,
name=f"agent-run-{run_id}"
)
try:
# 2. Chỉ truyền connection string của branch riêng cho agent
result = run_agent(
run_id=run_id,
database_url=branch.connection_uri
)
# 3. So diff và metric trước khi quyết định
diff = compare_with_baseline(branch.id, baseline_branch_id)
decision = evaluate_quality_gate(result, diff)
if decision == "promote":
promote_changes(branch.id)
else:
log_experiment_result(run_id, result, diff)
finally:
# 4. Dọn môi trường tạm dù agent thành công hay thất bại
delete_database_branch(branch.id)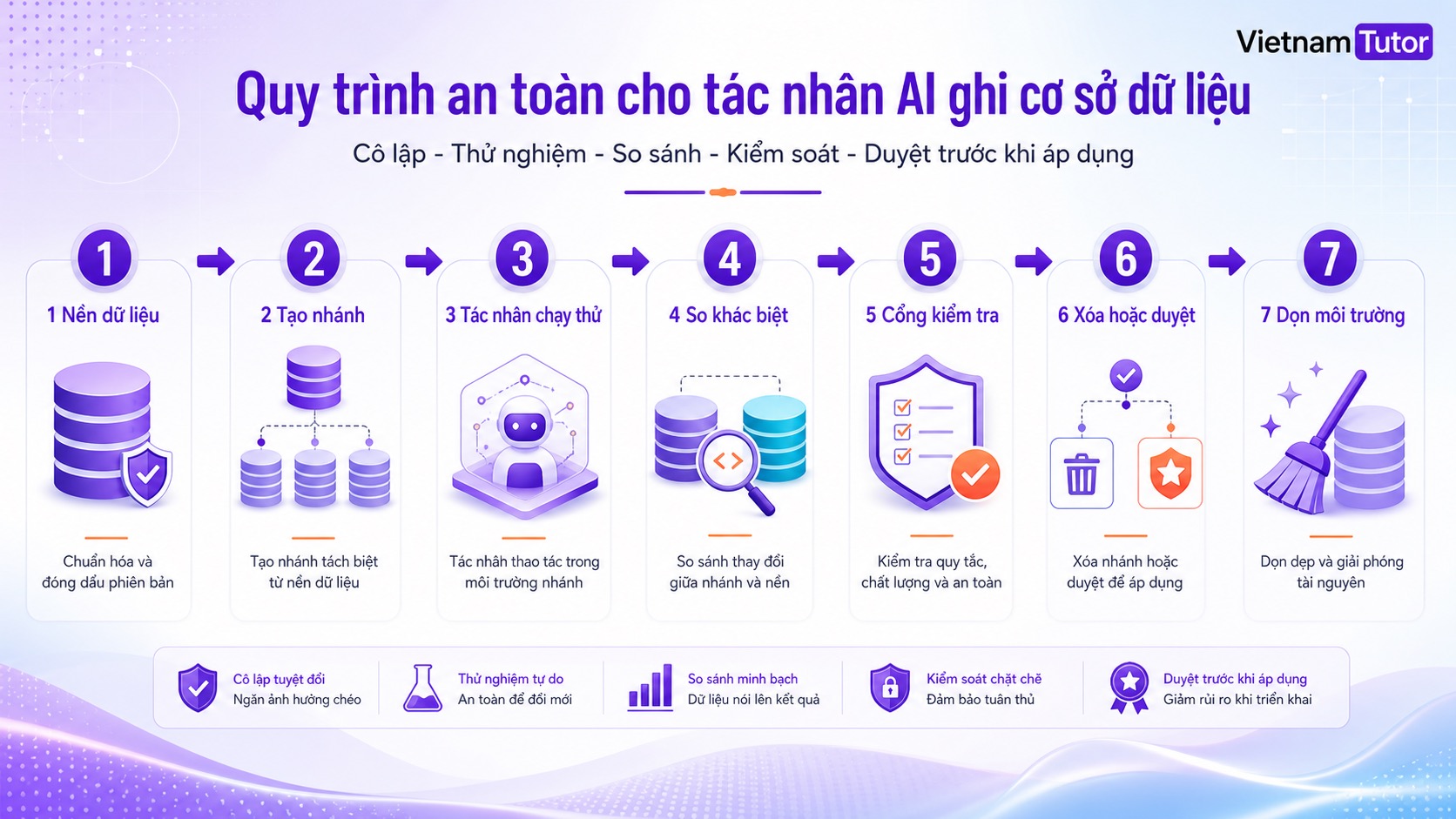
Khi nào cần fork riêng và khi nào read-only là đủ?
Bạn cần fork riêng khi agent có quyền ghi, chạy song song, thử migration, dọn dữ liệu hoặc cần benchmark có thể tái lập. Nếu agent chỉ đọc dữ liệu để trả lời câu hỏi hoặc tạo báo cáo, read-only replica thường đủ và đơn giản hơn.
Dùng fork riêng trong các tình huống sau:
- Migration test: agent đề xuất hoặc chạy migration schema, thêm index, đổi constraint, sửa kiểu dữ liệu.
- Data cleanup: agent gộp khách hàng trùng, chuẩn hóa trạng thái đơn hàng, sửa record lỗi.
- Parallel experiment: nhiều agent hoặc nhiều prompt cùng thử một bài toán từ cùng baseline.
- Benchmark reproducibility: cần đo agent nào tốt hơn với cùng dữ liệu đầu vào.
- Rollback-sensitive workflow: agent có thể tạo thay đổi lớn và bạn muốn xóa sạch môi trường nếu output không đạt.
Ngược lại, read-only là đủ khi agent chỉ phân tích doanh thu, trả lời câu hỏi nội bộ, tạo SQL gợi ý hoặc giải thích schema. Với nhóm này, ưu tiên tài khoản chỉ đọc, giới hạn network, query timeout và audit log.
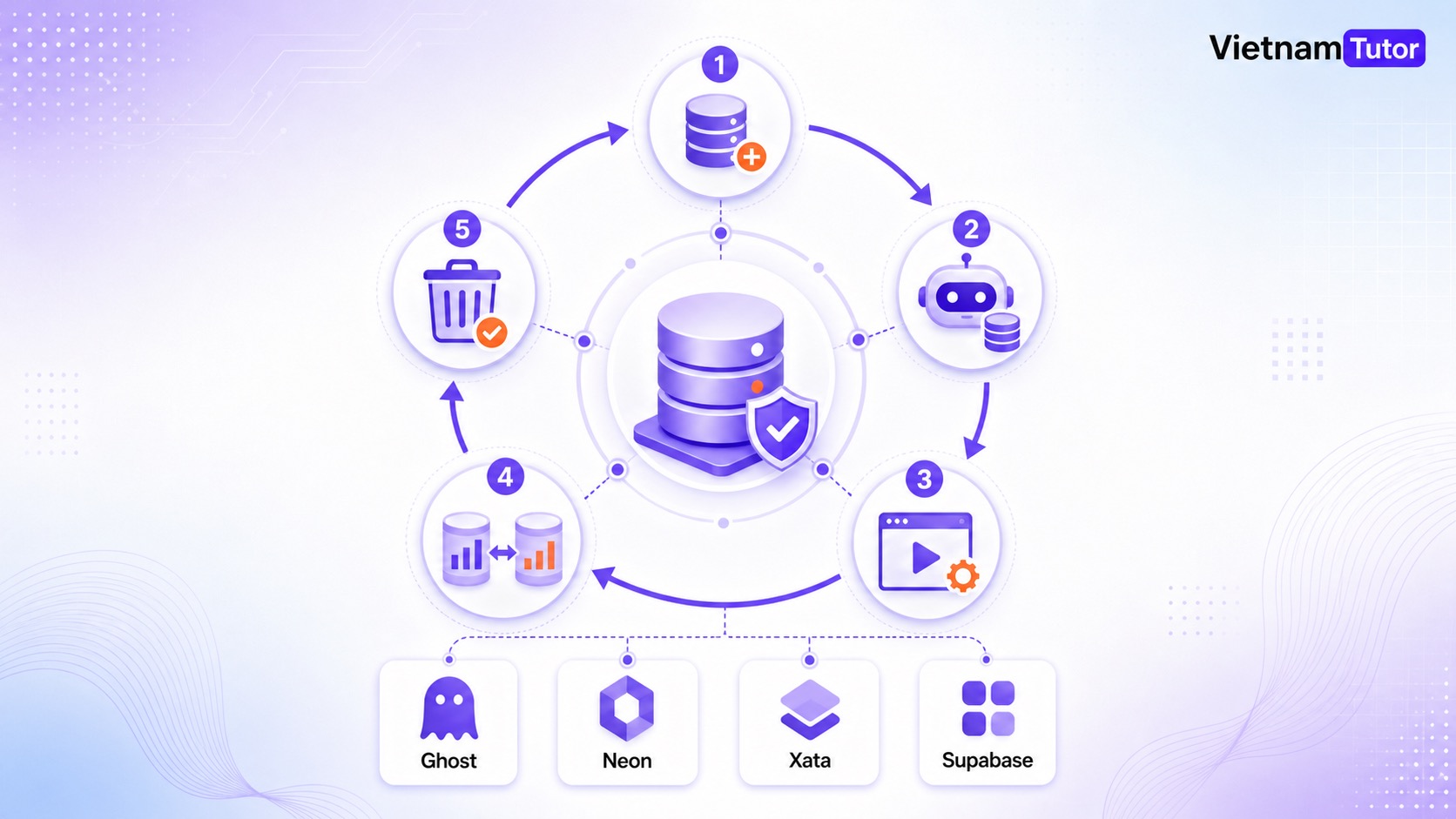
Ghost, Neon, Xata và Supabase nên hiểu thế nào?
Ghost nên được xem là một case study về lifecycle cho Postgres fork trong agent workflow; Neon, Xata và Supabase là các lựa chọn database branching/preview branch có phạm vi khác nhau. Đừng gọi “ghost forking” là thuật ngữ ngành nếu bài toán của bạn thực chất là database branching.
MindStudio dùng Ghost để minh họa cách tạo database riêng cho từng agent run, sau đó capture result, diff và cleanup [1]. Ghost docs cũng thể hiện hướng lifecycle bằng tool/CLI quanh thao tác tạo, fork, kết nối, chạy SQL, xem schema/log và xóa môi trường [6].
Neon có tài liệu riêng cho database versioning với snapshots trong ngữ cảnh AI agent và codegen platform, bao gồm preview branch, rollback và cleanup [2]. Xata hỗ trợ branch trong workflow phát triển database [3]. Supabase tập trung vào preview branch để thử thay đổi cùng migration và edge functions [4]. BranchBench, một benchmark học thuật năm 2026, cũng xem database branching như nhu cầu hạ tầng cho tác vụ agentic [5].
Điểm cần tỉnh táo: mỗi nền tảng có giới hạn khác nhau về merge, storage, snapshot, connection string, billing và cleanup. Thiết kế đúng là chốt rõ: agent cần ghi gì, dữ liệu có nhạy cảm không, cần rollback kiểu nào, ai được promote và môi trường tạm sống bao lâu.
Checklist an toàn trước khi cho agent ghi database
Trước khi cho agent ghi database, bạn cần kiểm soát dữ liệu nguồn, quyền truy cập, môi trường ngoài database, audit log và cleanup. Nếu thiếu các guardrail này, database branch chỉ tạo cảm giác an toàn giả.
- Không clone production data thô: dùng masked data, anonymized data hoặc subset đủ đại diện. PII không nên đi vào môi trường thử nghiệm nếu không cần.
- Least privilege: tài khoản agent chỉ có quyền cần thiết. Nếu chỉ sửa vài bảng, đừng cấp quyền toàn schema.
- Connection string theo run: orchestrator cấp database URL cho từng run. Agent không được tự đọc production URL từ global config.
- Timeout và budget: giới hạn thời gian chạy, số query, số row touched và chi phí branch/snapshot.
- Audit log: lưu run ID, baseline version, branch ID, prompt version, tool call và diff summary.
- External state: cô lập Redis, queue, search index, object storage và webhook/API có side effect. MindStudio cũng cảnh báo database không phải state duy nhất trong agent workflow [1].
- Promotion gate: promote phải qua test, review hoặc policy tự động rõ ràng. Agent không nên có quyền tự merge vào production.
- Cleanup bắt buộc: luôn có finally block hoặc job nền để xóa môi trường tạm, kể cả khi agent crash.
Nếu triển khai trong doanh nghiệp, bạn có thể liên kết pattern này với các quyết định lớn hơn như triển khai AI Agent không phụ thuộc nền tảng, kiểm soát dữ liệu và giọng thương hiệu cho AI Agent, hoặc hiểu rõ MCP là gì trước khi cho agent dùng tool có quyền ghi.

Nguồn tham khảo
- MindStudio: How to Build an AI Agent with Isolated Database Environments Using Ghost
- Neon Docs: Database versioning with snapshots
- Xata Docs: Branches
- Supabase Docs: Branching
- BranchBench: Aligning Database Branching with Agentic Demands
- Ghost Docs
Các câu hỏi thường gặp
Môi trường database cô lập cho AI Agent có phải là staging không?
Không hẳn. Staging thường là môi trường dùng chung trước production. Còn branch/schema/container cho agent thường ngắn hạn, gắn với từng run, rồi được discard hoặc promote sau khi so diff.
AI Agent chỉ đọc database có cần database branching không?
Thường là không. Nếu agent chỉ đọc, hãy ưu tiên read-only replica, tài khoản chỉ đọc, query timeout và audit log. Database branching cần thiết hơn khi agent ghi, sửa schema, chạy cleanup hoặc thử nghiệm song song.
Database fork có merge lại production giống Git không?
Không nên hiểu đơn giản như Git. Một số provider có workflow branch/preview/restore riêng, nhưng promote thay đổi database cần migration, diff, test và approval. Với dữ liệu production, tự động merge mù là rủi ro lớn.
Có thể dùng schema riêng thay vì provider hỗ trợ branching không?
Có. Với PostgreSQL, bạn có thể tạo schema riêng cho từng run và copy dữ liệu cần thiết vào đó. Cách này linh hoạt nhưng nặng hơn native branching vì bạn phải tự xử lý copy data, quyền truy cập, diff và cleanup.
Dữ liệu production có nên clone vào fork cho AI Agent không?
Không nên clone dữ liệu production thô nếu có PII hoặc dữ liệu nhạy cảm. Hãy dùng dữ liệu đã mask, anonymized hoặc subset đại diện. Nếu bắt buộc dùng dữ liệu thật, cần quyền hạn tối thiểu, audit log và chính sách retention rõ.
Database isolation đã đủ để AI Agent an toàn chưa?
Chưa đủ. Agent thường còn chạm cache, queue, search index, file storage, email, webhook hoặc API thanh toán. Nếu các hệ thống đó vẫn dùng chung, agent vẫn có thể tạo side effect ngoài database branch.
Tóm lại, database isolation không phải món trang trí hạ tầng. Nó là điều kiện để agent có quyền ghi vẫn có thể thử nghiệm, đo lường và rollback có trách nhiệm. Nếu bạn đang chuẩn bị cho agent chạm dữ liệu thật, hãy bắt đầu bằng ba câu hỏi: mỗi lần agent chạy, nó đang ghi vào đâu, ai duyệt thay đổi, và fork đó bị xóa khi nào?
Nếu bạn đã từng triển khai database branching cho agent workflow, hãy chia sẻ case của bạn: bạn xử lý diff, external state và promote thế nào?