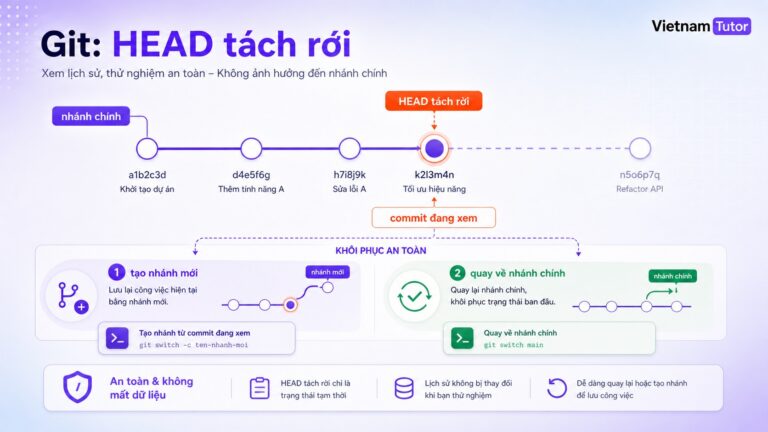
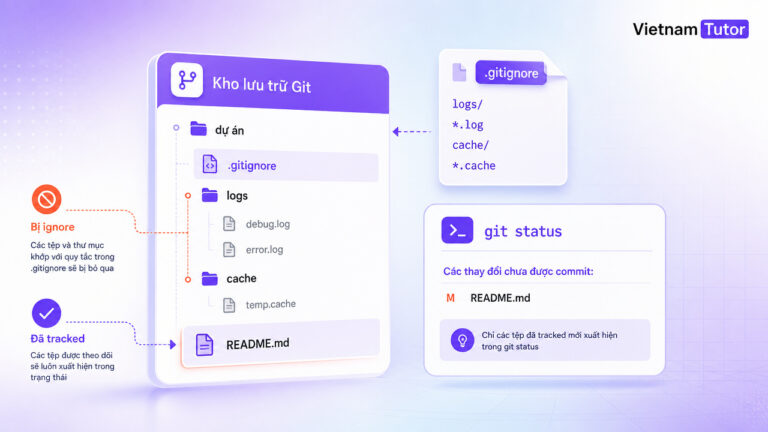
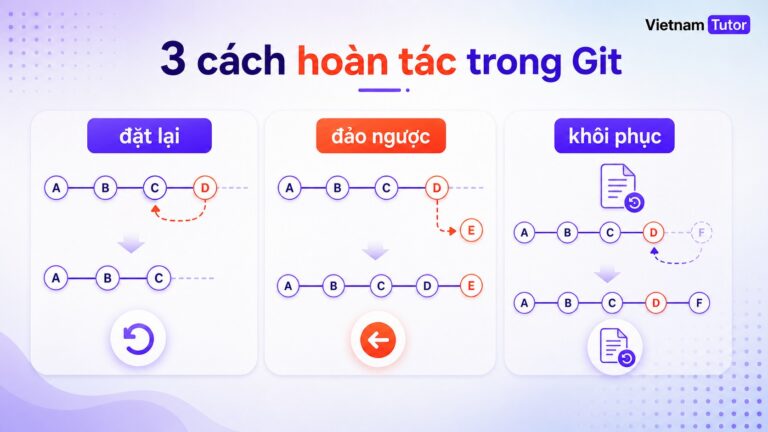
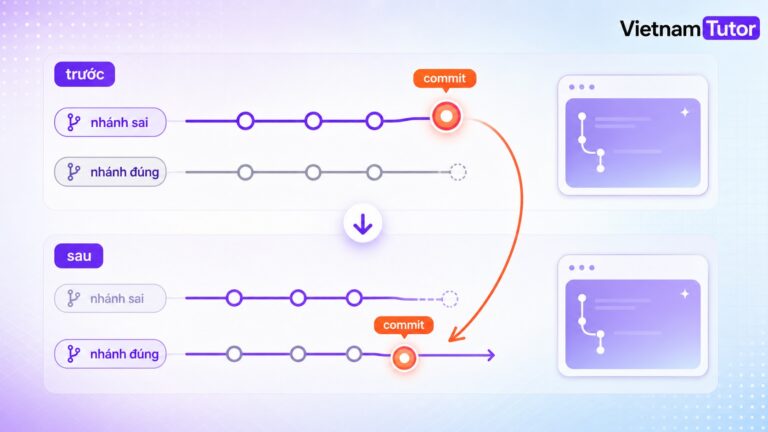
Các kỹ thuật tăng sức chịu lỗi cho chương trình:
- Tận dụng asynchronous communication: Hãy sử dụng asynchronous communication bất cứ khi nào có thể, đặc biệt là giao tiếp giữa các dịch vụ nội bộ, ví dụ như giữa các microservice. Bạn có thể sử dụng một message broker, hoặc áp dụng event-driven architecture. Sử dụng giao tiếp asynchronous giúp tránh lan tỏa các kết nối hay dịch vụ chậm, giả sử bạn có dịch vụ A phụ thuộc vào B, rồi B phụ thuộc C, nếu C chậm sẽ làm cả A và B chậm theo, và khi mạng lưới dịch vụ của bạn càng lớn, mức độ ảnh hưởng sẽ càng cao. Khi áp dụng asynchronous communication, bạn sẽ cần sử dụng mô hình eventual consistency, hay còn gọi là optimistic replication, vốn rất phổ biến khi làm việc với các mô hình phân tán, hoặc có lẽ bạn cũng đã nghe qua nó khi học về CQRS.
- Sử dụng timeout: đừng bao giờ chờ một dịch vụ khác mà không có timeout, có thể một lúc nào đó cả ứng dụng của bạn bị treo chỉ bởi một dịch vụ trong đó bị treo.
- Cung cấp một phương án dự phòng: nếu không thể gọi đến một dịch vụ nào đó thì bạn sẽ làm gì? Trả về một mã lỗi? Tất nhiên là vậy rồi, nhưng hãy cân nhắc một phương án dự phòng nếu có thể, ví dụ như trả lại dữ liệu có trong cache, hay trả về một giá trị mặc nhiên, nếu logic chương trình chấp nhận điều này, các phương án dự phòng sẽ giúp tỷ lệ lỗi giảm xuống đáng kể.
- ‘Retry: Khi gặp lỗi gọi một dịch vụ, đôi khi lỗi đó có thể chỉ là tạm thời, một microservice có thể không thể truy cập chỉ vì nghẽn mạng, hoặc đang bị chuyển từ node này sang node khác, vậy nên hãy thử lại một vài lần trước khi coi nó là không thể truy cập. Tuy nhiên có một lưu ý là bạn nên tăng thời gian chờ mỗi khi thử lại, ví dụ các lần thử lại có thể là sau 0.5-1-2-4-8, hoặc 0.5-2-8 giây, thay vì cứ sau mỗi 1 giây, vì xác xuất một dịch vụ “sống lại” sẽ giảm dần theo thời gian. Con số cụ thể là do bạn quyết định dựa trên mỗi dịch vụ, ví dụ các dịch vụ xử lý file, hay gửi email, đôi khi người ta có thể đặt thời gian thử lại lên đến đơn vị giờ, điều này giúp tránh việc bạn tự DOS chính các dịch vụ của bạn.

- Giới hạn số lời gọi dịch vụ ngay từ phía client: Nếu bạn đang thực hiện một vài lời gọi đến một dịch vụ và nó vẫn chưa thể hoàn thành, vậy việc thực hiện thêm lời gọi nữa có lẽ chỉ làm hệ thống trở nên quá tải hơn, vậy nên hãy kiểm soát ngay từ client với số lời gọi đồng thời được giới hạn phù hợp. Mẹo: Bạn có thể dùng Semaphore để kiểm soát điều này.
- Áp dụng rate limiting, kể cả cho các dịch vụ nội bộ: Rate limiting cho phép giới hạn số lời gọi đến, có thể dựa trên tổng số request đang xử lý, hoặc trên đơn vị thời gian như Slide Window hoặc Fixed Window.
- Sử dụng Circuit Breaker pattern: Circuit Breaker là một design pattern cho phép bạn trả về các lỗi ngay lập tức khi số lỗi đạt đến một giới hạn, hay nói cách khác là “ngắt” mạch. Sau một thời gian ta có thể thử lại và nếu không còn lỗi, “mạch” sẽ được đóng lại và có thể sử dụng như bình thường.
Happy coding!